2024年1月3日

ChatGPTはBERTやT5を消し去るのか?

AI技術の進歩により、自然言語処理の分野は目覚ましい発展を遂げています。
中でも、チャット形式で様々なタスクを手助けしてくれるChatGPTの登場はインパクトが大きく、その登場に合わせて大規模言語モデルの開発は世界中で大きく注目されています。
その盛り上がりの一方で、出現した当初は界隈を賑わせたBERTやT5のようなモデルはもうお役御免になってしまうのでしょうか?
例えば、ニューラル言語モデルが出現してからナイーブベイズやSVMなどのアルゴリズムが活用されることは本当に稀になりました。
歴史は繰り返され、ChatGPTを筆頭とした大規模言語モデルはすべてを飲み込んでしまうのでしょうか?
本記事ではBERTやT5などの従来的なAIモデルをChatGPTを代表としたGPTモデルと比較することで、その有用性について整理しながら解説を行います。
筆者は10年以上に渡って自然言語処理AIを活用した研究開発を行ってきましたが、本記事では技術面の詳細な話は避け、ビジネスの場面においての有用性を中心に比較を行います。
特に、実践的な比較を行うため幅広い範囲でタスク達成能力の高いChatGPT(特にgpt-4)をGPTモデルの代表として扱います。
将来的にローカル運用の可能なLLMのタスク達成能力が十分に向上した場合は論点にも変更が生じる点だけはご承知おきください。
【目次】
GPTとBERT, T5の違い
モデルの特徴を掴んでいただくため、簡単にですがアーキテクチャの違いについて紹介します。
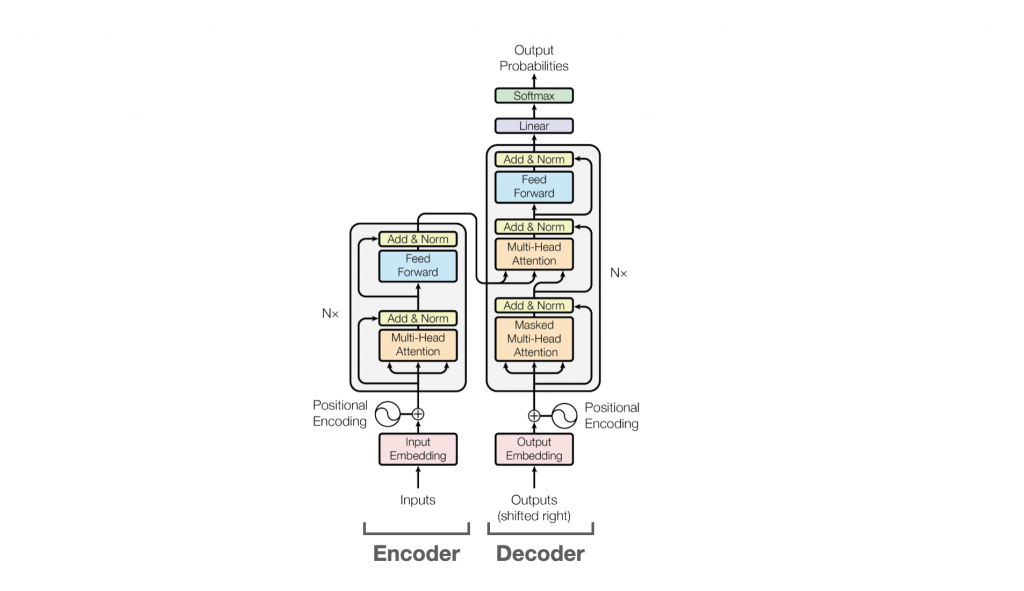
いずれのモデルにもTransfomerと呼ばれるモデルが着想の根本にあります。
Transformerは大きく2つのコンポーネントがあり、一つがEncoder、もう一つがDecoderと呼ばれます。
Encoderはテキストなどの入力を受け付けて潜在空間にマッピングします。Decoderはテキストや潜在空間表現などの入力から文章の生成を行います。
GPTはTransformerのDecoderの機能を持っており、BERTはEncoderのみを、そしてT5はEncoderとDecoderの双方を合わせ持つモデルです。
ChatGPTはその名前の通りGPT系のモデルに属します。
過去のAI分野においてはBERTは意味理解タスク(虫食い問題など)、GPTは文章の生成タスク(要約など)、T5はBERTとGPTの得意な領域のどちらのタスクにも対応できるように提案されてきました。
現在はLLMと表現するとChatGPTを代表としたパラメータ数の大きいGPT系列のモデルを暗に指すことが多くなりましたが、GPT-2時代では生成される文章は不自然なものばかりで、BERTやT5などの意味理解モデルが流行っていました。
またスケール則(Scaling Laws)が証明されてからAI開発に資金が流れ込む速度が向上し、OpenAIによるChatGPTを筆頭とした現在のLLMが生まれてきたという歴史の流れがあります。
(*1) https://arxiv.org/pdf/1706.03762.pdf
そもそもなぜ比較されるようになったのか?
過去のGPT系のモデルは翻訳や要約、チャットボットの発話生成、広告クリエイティブの作成などのテキスト生成が必要な応用場面ごとに専用のモデルを構築するアプローチが主流でした。
ChatGPTが出現してからは、「次の文章を要約してください」、「日本語に翻訳してください」といった文章(プロンプト)を活用することで、単一のモデルで幅広いタスクを達成できることが広く知れ渡り、一つの大きな言語モデル(LLM)の構築が目標とされるようになりました。
この汎用性の広さから、従来的にはBERTやT5などを活用して解くようなタスクであってもGPT系のモデルを適応することができるようになったことから、アーキテクチャの違いはあっても比較対象にできるようになったという事情があります。
BERTやT5がChatGPTより優れている場面
結論から述べると、BERTやT5で達成が可能なタスクでは1.ランニングコストと2.処理効率の高さの観点から採用される事例は未だに多いです。
実際にChatGPTをプロジェクトに活用できないか?といった相談は数多くいただいておりますが、上記の理由からChatGPTを使用しない形でのAIモデルを活用したアプリ開発をオススメするケースがあります。

1.ランニングコスト
従来的なAIの運用においては一般的なWebアプリ等とは異なり、GPUと呼ばれる行列計算に特化したハードウェアが必要になります。
オンプレの場合は購入した瞬間にのみ費用が発生し、AWSなどのクラウドの場合は毎月使用量が発生します。
AWSの場合は、一番安価なGPUインスタンスであれば月10万円前後で使用することができ、文章の処理が十分に間に合っている限りは処理する文書の数に関わらず、一律で前述の価格がランニングコストになります
一方で、ChatGPTはリクエスト(厳密には文字の量)による従量課金になります。
従って、処理する文書の量が増えるほどにランニングコストが高くなります。
OpenAIのGPT系モデルを医療文書の処理に活用する検討を行ったことがあるため、試算の例をご紹介します。
- 仮検証からgpt3.5-turboではなくgpt-4レベルの能力が必要という条件が判明*
- この条件からプロンプトと文書内の平均的なトークン数から1文書あたり40円の従量課金が必要
- 月あたり5万件規模の文書を処理する必要があり200万円/月(年間2,400万円)の予算が必要
以上のように計算費コストだけで年間で2,400万円が必要であることがわかります。
これは条件が変わらない限り毎年請求される金額になります。
一方で、BERTやT5モデルなど従来手法をベースに開発を行う場合の試算は以下になります。
- 専用モデルの開発費:100万円〜1,000万円(当然にケースバイケースですが、モデル開発のみで発生しやすい価格帯を掲載しています)
- 保守費(月10万円〜)
- 計算費コスト:単一モデルで10万円ほど(AWSなどのIaasを前提、冗長化構成を組む場合は20万円〜)
総コスト = 1. 開発費+2.保守費(人件費)+3.計算費コストなので、
1年目は1,000万円+120万円+120万円= 1240万円
2年目以降は120万円+120万円= 240万円
となります。
ご覧のようにOpenAIモデルをベースとする場合は計算費コストだけで従来手法の総コストを上回ります(gpt-4の場合、5年後には計算費コストだけで億を超えます。)。
OpenAIのgpt-4を使用する場合は従量課金であるため単純に処理件数が増えるに比例してコストも高くなりますが、モデルを運用する場合は保守費込みでも月22万円〜の費用が必要になるだけです。
以上のようにランニングコストの観点はどのようなモデルを採用すべきか判断する大きな要因になります。
OpenAIを代表とした従量課金型の生成AIしか扱えない業者に発注する場合は、この観点を見落としがちになってしまう点には気をつけておくとよいです。
(*補足)
他にもgpt-3.5-turboでファインチューニングを行うというアプローチもありますが、料金がgpt3.5系とgpt-4系の中間ほどであり、またファインチューニングを行う場合は開発費が従来的なAI開発並みに必要になることから、たいていの場合はコスパがよくないという結果に落ち着くことが多いです。
一方で、適しているシーンはあるため、今後別の記事で紹介予定です。
2.処理効率の違い
BERTやT5などのモデルで達成できるタスクでは、ChatGPTよりもこれらのモデルの方が処理効率が優れます。
処理効率の違いによって、結果を得るまでの所要時間やGPU使用量による金銭的コストに影響が及びます。
ChatGPTは前述のように幅広いタスクに適応できるポテンシャルがあるという汎用性の高さが光りますが、タスク特化に処理効率をチューニングすることが困難という弱点があります。
イメージとしては、AIで解決できる領域が人間に近づいたため、計算時間や燃費も人間並に近づいてしまったといえます。
特に処理速度についてはアプリケーションによっては重要視すべき点になります。
BERTやT5ベースの手法では0.5秒で処理できるタスクが、gpt-4では30秒以上かかることも珍しくありません。
ちなみにgpt3.5-turboは速いですが、それでも5秒以上は時間を要する上にタスク達成の品質が不十分なケースが経験上かなり多いです。
ChatGPTがBERTやT5よりも優れている場面
テキスト生成の質
本稿の読者は日常的にChatGPT(Webアプリ)を使用していると思いますので詳細な説明を行う必要はないと思いますが、翻訳や要約、調査業務*、アイデアの壁打ちなどで日常的に使用している方が多いのではないでしょうか?
上記のような、どのようなタスクにも対応できる点がChatGPTの魅力であることは周知の通りです。
ちなみに、BERTは特殊なアダプタを使用しないとテキスト生成が行えないため積極的に採用する理由がなく、またT5をベースとしたモデルから開発を行うよりもChatGPTを使用する方が生成されるテキストの品質が高い傾向があります。
この理由については主にパラメータ数と学習データ量に関連しますが、T5に不足しているものがあるというよりはGPTのアーキテクチャで行える操作で十分かつ取り回しが簡単なため、ChatGPTはGPTベースに開発が行われたといえます。
(*補足)
厳密には調査業務でChatGPTを使用することはOpenAI社が述べているように非推奨な活用方法ではありますが、コーディングやライブラリの使い方などIT系業務には強い面がありますし、プラグインを適切に活用してRAG形式で使用すれば調査業務にも活用できます。
簡易版AIの作成が簡単
BERTやT5を使用する場合は、どんなに簡単なタスクであっても目安100件以上のデータは必要になることが多く、準備に時間がかかります。
またデプロイや保守の業務も合わせて担当する必要が出てきてしまいます。
その一方で、ChatGPT(gpt-4)などを使用する場合はfew-shotを含めたプロンプティングだけで達成できることも多く、小規模開発に向いています。
ただし実際にはgpt-4を使用してAIアプリのα版を作成しよう!とならないことがほとんどです。
前述のように、ビジネスの観点からランニングコストは抑えておく必要があり、そのコストを抑えるためにはOpenAI製ではない自前で運用できるAIモデルの開発が必要であり、その自前のAIモデルの処理能力が十分なのかを検証するPoCが優先されるためです。
ChatGPTの小規模開発は、以下のような自社内でしか使用しないような便利AIを作成する場合などには重宝します。
- 特定のメディアの記事を日本語に翻訳して自社のslackに投稿する
- webページから法人情報を抜き出して営業リスト作成をサポートする
AI開発にはどのようなモデルを採用すべきか?
本記事でご紹介してきたように、解決するタスクの特性によって適切なモデルは異なります。
ここまでの知見を総合すると、テキスト生成が必要な場合はChatGPTを、それ以外の出力を事前に設計できる場合はBERTやT5を採用する、といった方針が採用されやすい傾向にあります。
一方で、AI開発の経験の少ない開発者はあらゆる問題会解決をChatGPTに任せてしまい、性能的にもコスト的にもChatGPTでできないことは現在のAI技術の限界である、と説明してしまうケースも少なくありません。
もしAI開発を委託したいと思っており、またその作り方が十分に理解できていないと感じている場合は、ChatGPTの出現以前からAIソリューションやAIに特化したコンサルティングサービスを提供している実績が豊富な事業者をパートナーに選ぶことが推奨されます。
AI受託開発のノウハウについては以下の記事にまとめていますので、合わせてご覧いただければ幸いです。
AIベースの業務アプリ開発を専門としたコンサルサービスを提供しています。
生成AI以前から自然言語処理や対話システムを中心に研究開発してきました。対話戦略を組み込んだチャットボットや文書チェック系プロダクトの0→1開発が主領域です。
AI×医療,法律、金融、不動産分野における新規事業の創出を手掛けてきた経験から執筆します。
【所属】
株式会社サイシキ
言語処理学会(正会員)
人工知能学会(正会員)
日本メディカルAI学会(正会員)
早稲田大学人間科学学術院 招聘研究員
X(旧Twitter)も始めました、お気軽にコミュニケーションください https://x.com/shohei_fujikura
生成AI以前から自然言語処理や対話システムを中心に研究開発してきました。対話戦略を組み込んだチャットボットや文書チェック系プロダクトの0→1開発が主領域です。
AI×医療,法律、金融、不動産分野における新規事業の創出を手掛けてきた経験から執筆します。
【所属】
株式会社サイシキ
言語処理学会(正会員)
人工知能学会(正会員)
日本メディカルAI学会(正会員)
早稲田大学人間科学学術院 招聘研究員
X(旧Twitter)も始めました、お気軽にコミュニケーションください https://x.com/shohei_fujikura