2023年11月8日

【デモ付き】ChatGPTのファインチューニングのやり方は?どんな時にする?

2023年8月22日にOpenAIからChatGPT(gpt-3.5-turbo)のファインチューニング機能が公開されました。
AIのモデルパラメータを直接更新するファインチューニングを行うと、今までプロンプティングをどれだけ試してもうまくいかなかった課題を解決できる可能性があります。
一方で、ChatGPTの出現からAIを触り始めた方からは、「ファインチューニングの方法がわからない」、「ファインチューニングをどのようなタイミングで検討するべきなのかがわからない」という質問をよくいただきます。
本稿では、まだLLMに対してファインチューニングを行ったことがない方を対象として、どのような場面でファインチューニングを行うのか、そしてどのような手順でChatGPTファインチューニングを行うのかについて解説します。
最初に本記事における用語の整理を以下に示します。
・ChatGPT:API版のGPT-3.5やGPT-4などの生成AIモデルのこと
・プロンプト:生成AIに入力する指示のこと
・プロンプティング:良い結果を得るためにプロンプトを試行錯誤して設計すること
どんな時にファインチューニングをするのか?
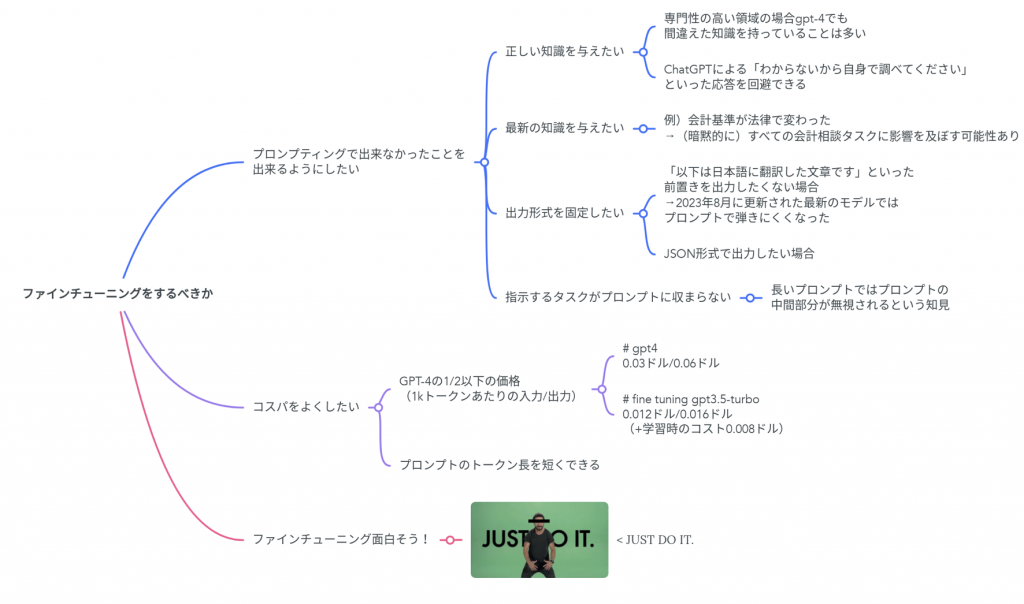
ファインチューニングの意思決定に関するマインドマップを掲載しました。
以下ではこのマインドマップと同様の説明を行います。
プロンプティングで出来なかったことを出来るようにしたいとき
基本的な指針として、プロンプティングを色々と試してみて、それでも上手くいかなかった時にファインチューニングを試してみる、という流れが良いです。
以下に、ファインチューニングの検討を進めるべき場面を4パターン挙げます。
1. 正しい知識を与えたいとき
専門性の高い領域ではChatGPTにおいても意味が理解できていない場面が頻出します。
この場合は専門領域の書籍などを媒介としたデータセットを準備してファインチューニングを行うと課題がスムーズに解決できるようになる可能性があります。
また、ChatGPTにとって不明確な情報は出力しないように制限がかかることが多いため、この問題に対策したいシーンもあります。
2. 最新の知識を与えたいとき
例えば会計基準が法律で変わった場合など、生成モデルにおける会計タスクのすべてに影響を及ぼしたい場面があります。
表面的な情報の変化というよりも、根本的な前提条件を最新の状態に反映したい場合は、ファインチューニングが適しています。
表面的な情報の変化に追従したい場合は、RAG(Retrieval Augmented Generation)によるアプローチで十分なケースもあるので、検討の順番には気をつけてください。
3. 出力形式を固定したいとき
ChatGPTはその名前の通り、チャット形式でタスクの達成を目的とした生成AIとなります。
その副作用として、端的に依頼したタスクの結果を掲載してほしい場面でも、前置きが出力されてしまうケースがあります。
例えば、「記事を日本語に翻訳してください。翻訳結果だけ出力してください。」というタスクを投げた場合であっても、「はい、以下は日本語に翻訳した記事になります。…」というように前置きが出力されてしまうことがあります。
他にも専門領域では「私は会計士ではないので…」といったアナウンスは頻出します。
アプリケーションの中にChatGPTを組み込んでいる場合、このような前置きは必要がないケースが多く、それどころか前置きを削除する処理が必要になり、手間がかかってしまいます。
上記と同じようなシチュエーションで、JSON形式で出力したい場合であっても、前置きがあるとJSONのパースに失敗してしまいます。
このように、出力する形式をきっちりと定めたい場面において、ファインチューニングを行うことも視野に入れてよいでしょう。
考察:2023年8月更新のモデルは、なぜ前置きを積極的に出力するようになったのか?(クリック)
生成AIについて、Chain of Thought(CoT)という思考を明示的に記述することでタスクの達成度が向上するという知見があります。 おそらくですが、OpenAIはCoTを目的としたInstruction Tuningを行ったため、このような前置きが表示されてしまう傾向が強くなってしまったものと考察しています。
4. 指示するタスクがプロンプトに収まらないとき
例えば多くの単語を含む文章に対して、詳細なプロンプトを活用してタスクに適応する場合、トークサイズの上限に達してしまうケースがあります。
この場合は基本的に、よりトークンサイズの上限が高いモデルを採用することが求められますが、生成AIにおいてはプロンプトの中間部分が無視される傾向にあるという知見が広まっており、単純にトークンサイズの上限を上げるだけでは解決できない場合があります。
このようなシーンでは、詳細なプロンプト部分をパラメータに埋め込むファインチューニングを行うことで、対応ができることがあります。
また後述しますが、従量課金の計算上トークンサイズが長くなるほどに費用もかかるため、単純にトークンサイズを抑えたい場面はよく発生します。
コスパを良くしたいとき
GPT3.5のファインチューニング済みモデルは、一般的なGPT-3.5と比較してパフォーマンスを引き出せる一方で、GPT-4よりも圧倒的に安い料金でモデルを運用できる可能性があります。
公式のOpenAIによるとGPT-4よりもファインチューニング済みGPT3.5の方が性能が高いケースもあるとのことです。
特に料金について、GPT-4は入力時トークンと出力時トークンがそれぞれ0.03ドル/0.06ドルとなっている一方で、fine-tuning gpt3.5-turboは0.012ドル/0.016ドルと約1/3ほどの費用で運用することができます。
※ 学習時には追加で0.008ドルの料金がかかります。
ここまでにシンプルにトークンあたりの費用が安いことを確認しましたが、そのトークン長そのものを低減することもファインチューニングモデルでは可能になります。
例えばGPT-4で翻訳を行うシーンにおいて、英単語を旧来的な日本語に変換するのかそれともカタカナ語として扱うのか等、出力の出来をよくするためにプロンプトに細かく指示を記載する必要があり、トークン数もそれだけ長くなります。
一方で、ファインチューニングモデルの場合「日本語に翻訳してください」という指示だけでデータから自動で学習を行ってしまうことが可能な場合があります(実際には性能を検証する必要があります)。
つまり、GPT-4ではプロンプトに指示していたトークン分を、すべて生成AIのパラメータに埋め込むことができるため、実際に使用する入力トークン数を大幅に低減することができます。
このように、トークン数自体を減らすことも可能なため、ファインチューニングを行うとコストの低減が大幅にできます。
料金についてはOpenAIの以下のページで確認することが出来ます。
https://openai.com/pricing
ファインチューニング面白そう!と思っている場合
今すぐやりましょう!!!!

ファインチューニングのやり方
ここからはgpt3.5-turbo-0613のファインチューニングを行う方法について解説していきます。
末尾に0613と記載がありますが2023年の6月13日に公開されたモデルという意味となりますが、現在はgpt3.5はこのモデルしかベースにできないため、気にする必要はありません。
基本的には以下のOpenAIのファインチューニングに関するページを参照するだけ…と思っていたのですが、記述が不完全な部分が多く、簡単には再現できませんでした。
https://openai.com/blog/gpt-3-5-turbo-fine-tuning-and-api-updates
この記事では、OpenAIによるチュートリアルの不完全な部分についても説明を加えながら、デモを通してファインチューニングを行います。
デモにおけるファインチューニングの目的
個人的な話題で恐縮ではありますが、AIに関する海外の記事をたくさん読む必要があるため、このタスクを効率化したいです。
したがって、今回のテーマは「ある記事を入力した時に、積極的に読むべき記事かそうでないのかを2値で判別できるようなモデルの構築」としたいと思います。
ファインチューニングなしでこのタスクを行おうとすると、few-shot形式でプロンプトの中に記事本文と読むべきか否かを列挙する必要があり、プロンプトに入力する記事本文のトークン数が莫大になります。
また、json形式の出力を行うことで、後続の処理に繋げやすくすることも目的とします。
したがって、この事例は前述のファインチューニングの意思決定における「3. 出力形式を固定したいとき」と「4. 指示するタスクがプロンプトに収まらない」に該当します。
ファインチューニングの手順
データの準備
今回設定したタスクでは、以下のようなデータを準備しました(read_or_not.jsonlと命名)。
例えば製品や事例の紹介は興味ありに、AI企業の銘柄の株価予測などのトピックは興味なしとしました。
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "Consulting giant McKinsey unveils its own generative AI tool for employees: Lilli"}, {"role": "assistant", "content": "{'label':1}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "In Battle With Microsoft, Google Bets on Medical AI Program to Crack Healthcare Industry"}, {"role": "assistant", "content": "{'label':1}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "Your next job interview could be with AI instead of a person"}, {"role": "assistant", "content": "{'label':1}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "Chat GPT for contract drafting: AI v. templates"}, {"role": "assistant", "content": "{'label':1}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "Amazon is using generative A.I. to summarize product reviews"}, {"role": "assistant", "content": "{'label':1}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "ChatGPT meets Robinhood? New investing app features AI-powered portfolio mentor"}, {"role": "assistant", "content": "{'label':1}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "5 myths about medical AI, debunked"}, {"role": "assistant", "content": "{'label':1}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "BIG DATA IS DEAD"}, {"role": "assistant", "content": "{'label':0}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "Monarch Tractor CEO Praveen Penmetsa is coming to the Code Conference"}, {"role": "assistant", "content": "{'label':0}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "Modular looks to boost AI mojo with $100M funding raise"}, {"role": "assistant", "content": "{'label':0}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "Watch out, Midjourney! Ideogram launches AI image generator with impressive typography"}, {"role": "assistant", "content": "{'label':0}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "31% of investors are OK with using artificial intelligence as their advisor"}, {"role": "assistant", "content": "{'label':0}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "Nvidia earnings scare away AMD, Intel investors as legacy chipmakers lose ground in AI"}, {"role": "assistant", "content": "{'label':0}"}]}
{"messages": [{"role": "system", "content": "記事を読むべきか0か1で判別してください"},{"role": "user", "content": "Jim Cramer’s top 10 things to watch in the stock market Thursday"}, {"role": "assistant", "content": "{'label':0}"}]}システムプロンプトは固定し、userのcontentには記事のタイトルを入力しています。
また、アシスタントのcontentにはそのままJSONパースできるような形式にしています。
本来であれば記事本文をもっと追加したり、重要な単語を明記することで意図に近い分類ができるようになることが想定されますが、まずは簡易なデモで能力を確認します。
また執筆時点では明示されていませんでしたが、ファインチューニング用のデータは最低でも10件以上は必要と条件付けられているため、データセットの分量にはご注意ください。
データのアップロード
公式のOpenAIがcurlコマンドでの例を取り上げていたので、本稿でもこちらを踏襲します。
事前に環境変数$OPENAI_API_KEYにOpenAIから発行される鍵を設定しておくか、変数$OPENAI_API_KEYの部分をsk-で始まる鍵をそのまま埋め込むかして実行してください。
まずは上記のデータセットをOpenAIのサーバにアップロードします。
入力
curl https://api.openai.com/v1/files \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@@read_or_not.jsonl"出力
{
"object": "file",
"id": "file-***",
"purpose": "fine-tune",
"filename": "output.jsonl",
"bytes": 6499,
"created_at": 1692950191,
"status": "uploaded",
"status_details": null
}id部分は後続の処理で使用することになりますので、どこかに控えておきましょう。
また、アップロードとパース成否の判定は別のようですので、アップロードしたファイルが見つからないとエラーが出るようであれば、以下のリクエストで状況の確認ができます。
curl https://api.openai.com/v1/files/file-*** -H "Authorization: Bearer $OPENAI_API_KEY"JSONのパースに失敗していると以下のような結果になっています。
{
"object": "file",
"id": "file-***",
"purpose": "fine-tune",
"filename": "read_or_not.jsonl",
"bytes": 3521,
"created_at": 1692972315,
"status": "error",
"status_details": "Invalid file format. Example 15 cannot be parsed. Error: line contains invalid json: Expecting value: line 2 column 1 (char 1) (line 15)"
}成功している場合は以下のようにstatusがprocessedになっています。
{
"object": "file",
"id": "file-***",
"purpose": "fine-tune",
"filename": "read_or_not.jsonl",
"bytes": 3520,
"created_at": 1692972666,
"status": "processed",
"status_details": null
}ジョブの作成
json部分のtraining_fileには上記で取得したfile-で始まるIDを入力してください。
入力
curl https://api.openai.com/v1/fine_tuning/jobs -H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{"training_file": "file-***","model":"gpt-3.5-turbo-0613"}'出力
{"object":"fine_tuning.job",
"id":"ftjob-***",
"model":"gpt-3.5-turbo-0613",
"created_at":1692950737,
"finished_at":null,
"fine_tuned_model":null,
"organization_id":"org-***",
"result_files":[],
"status":"created",
"validation_file":null,
"training_file":"file-***",
"hyperparameters":{"n_epochs":7},
"trained_tokens":null}JSON形式で出力が返ってくるので、ftjob-***で始まるジョブIDと、org-で始まる組織IDを手元に控えておいてください。
ジョブの状態を取得
ジョブを発行した段階でcreatedになっていればファインチューニングが開始されています。
ジョブが完了するとOpenAIから自動でメール通知が来ますが、その前にどのような状況なのか確認したい場合は以下のようにGETメソッドでステータスを確認することができます。
入力
curl https://api.openai.com/v1/fine_tuning/jobs/ftjob-*** -H "Authorization: Bearer $OPENAI_API_KEY"出力
{"object":"fine_tuning.job",
"id":"ftjob-***",
"model":"gpt-3.5-turbo-0613",
"created_at":1692950737,
"finished_at":null,
"fine_tuned_model":null,
"organization_id":"org-***",
"result_files":[],
"status":"running",
"validation_file":null,
"training_file":"file-***",
"hyperparameters":{"n_epochs":8},
"trained_tokens":null}この結果ではstatusがrunningになっているため、まだファインチューニングしていることがわかります。
もう少し時間をおいてから同じようにリクエストを出してみます。
{"object":"fine_tuning.job",
"id":"ftjob-***",
"model":"gpt-3.5-turbo-0613",
"created_at":1692950737,
"finished_at":1692951347,
"fine_tuned_model":"ft:gpt-3.5-turbo-0613:***",
"organization_id":"org-***",
"result_files":["file-***"],
"status":"succeeded",
"validation_file":null,
"training_file":"file-***",
"hyperparameters":{"n_epochs":8},
"trained_tokens":9568
}statusがsucceededになっていることがわかります。
ファインチューニングが完了するとfine_tuned_modelにft:gpt-3.5-turbo-0613:組織名***という名前でモデルが作成されます。
この名称は今後モデル活用を行うときに毎回使うので、しっかりとメモに残しておきましょう。
ファインチューニング済みモデルを使う
jsonのmodelパラメータにfine_tuned_modelの名称を指定してください。
入力
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{ "model": "ft:gpt-3.5-turbo-0613:***", \
"messages": [{"role": "system", \
"content": "記事を読むべきか0か1で判別してください"}, \
{"role": "user", \
"content": "Meta releases Code Llama, a new open-source LLM geared for programming"}]}'出力
{
"id": "chatcmpl-***",
"object": "chat.completion",
"created": 1692976032,
"model": "ft:gpt-3.5-turbo-0613:***",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{'label':1}"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 45,
"completion_tokens": 5,
"total_tokens": 50
}
}OpenAIのPlaygroundでも試すことができます。
右手側のModelからファインチューニング済みのモデルを選択する点だけ忘れないようにしてください。
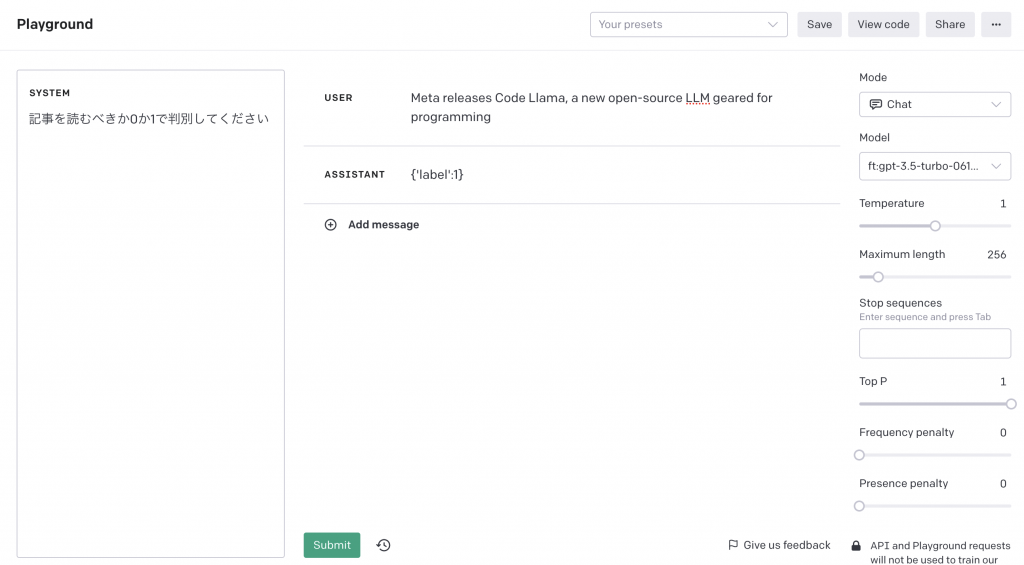
デモ画像の出力が{‘label’:1}になっていることから、この記事は”読むべき”という結果が得られました。
出力形式に関しても期待した通りのJSONパースができるような結果になっています。
この結果をもとに、例えばRSSで情報をリスニングし、”読むべき”と判断されたらSlackで通知をするなど実用性が高い形で連携することができるようになりました。
この簡易な例では大きな恩恵にはなりませんが、”JSON形式で出力してください”といったプロンプトを追加することなく自動でJSON形式で出力してくれる点にも注目したいです。
ファインチューニングによってプロンプトに必要なトークン数が少なくなり、コスト低減のメリットに繋がっていることがわかります。
さいごに
本記事ではどのような段階でファインチューニングを検討するのか、そして実際にどのようにしてファインチューニングを行うのかデモを通じてご紹介しました。
ファインチューニングで達成できることはやや地味であり、現時点では魅力を感じている人もそこまで多くはないのかもしれません。
特に、プロダクトの性能を少しでも向上させたい、プロダクトが売れて従量課金が重いからランニングコストを下げたいなど、エンジニアリングの先にファインチューニングの必要性が高まることにも起因していると思います。
頭の片隅にファインチューニングというものもあるのだなぁと思っていただいて、必要な時に改めて本記事を参考にしていただければ幸いです。
また、今回お話した以外にも気をつけるべき点はいくつかあり、例えばエポック数や学習率といったハイパーパラメータの指定がその一つに挙げられます。
特に学習率周辺のパラメータは過去のAI開発の経験からすると、かなりセンシティブな要因になりますが、まだ公開されたばかりで十分には検証できていないため、今後も何らかの形で知見を共有できればと思っています。
冒頭のファインチューニングの意思決定に対するマインドマップを含め、本記事の知見がお役に立てたようであれば重畳です。