2026年5月11日

意味検索サービス事業者によるベクトルデータベースの比較

文書の意味検索サービスを提供するベンチャー企業のvectorviewがベクトルデータベースの比較を公開しており、本記事にてご紹介いたします。
同社は文書とユーザの関連性を計算するため文書やユーザのベクトル表現について数多くの比較研究を行ってきています。
また、ベクトルデータベースは数多くの企業が提供しており、それだけ独自性の高い強みとトレードオフとなる弱みがあることが想定されます。
本記事ではLLMでベクトルデータベースを活用することも想定した上でベクトルデータベースについてご紹介します。
最初に、ベクトルデータベースの基礎知識やどのような場面で活用するのかという基礎知識についてご案内いたします。
LLMとベクトルデータベースを連携するメリット
ベクトルデータベースは、ベクトルの保存や検索などの操作に特化したデータベースになります。
一般的なRDBMSとは異なり直接リレーション付けを行うような操作はないですが、このDBで管理するベクトルに対して内積計算を行うことでアイテム間の類似度を算出するといった活用が行えるようになります。
特にChatGPTの台頭と共に着目される機会が増えてきており、ChatGPTの苦手な最新のニュースや公開されていない情報の扱いなどの弱点を補うために合わせて使用されます。
ベクトルデータベースを使用してRAGと呼ばれる構成を組むと、具体的にはそれぞれニュース記事へのQAや社内の情報に特化したチャットボットなどを構築することができるようになります。
ベクトルデータベースの比較項目
ベクトルデータベースにはPineconeなどのDaas製品や、WeaviateやMilvusのようにOSSで公開されており自身でホスティングできるものがあります。
ベクトルデータベースを選ぶ際には、一般的なデータベースの選定基準と同様なスケーラビリティ、レイテンシ、コスト、コンプライアンスなどを考慮する必要があります。
また、開発者の経験、コミュニティの強さ、セキュリティ機能なども重要な要素です。
ベクトルデータベースに特徴的な項目ですが、料金がレコードの数だけではなく保存するベクトルの次元数によっても変化が生じる点に注意してください。
次元数が多いほど必然的に情報が多くなり、必要な容量が多くなるためです。
ベクトルデータベースの比較結果
vectorviewが作成したベクトルデータベースの機能比較表を以下に見ていきます。
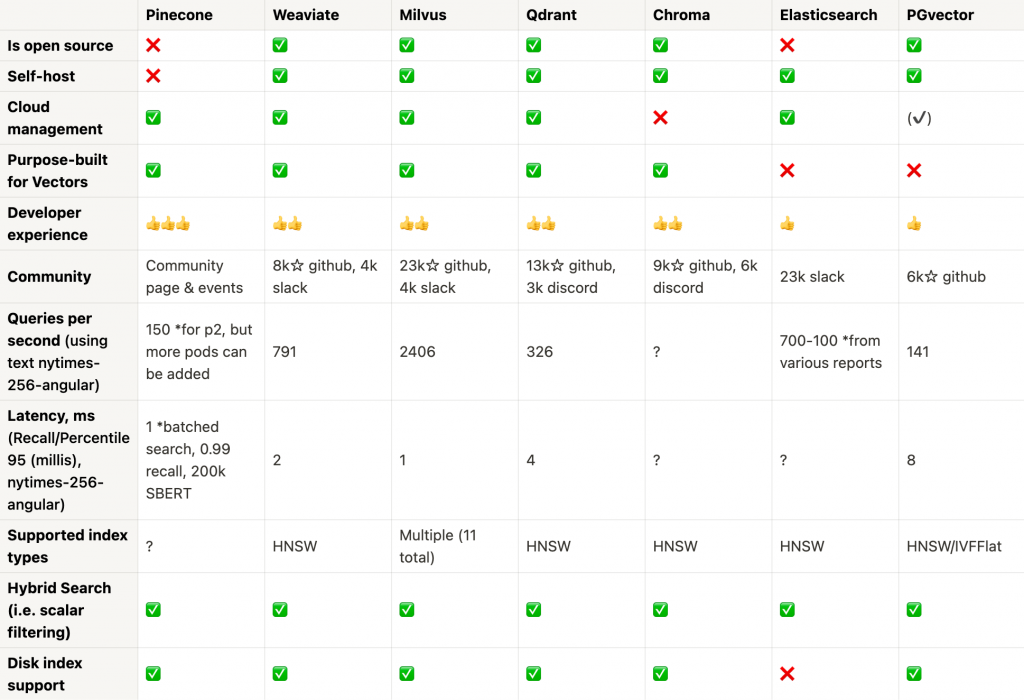
表の作成者(vectorview)によると以下のようにまとめられています。
OSSかクラウドか
OSSを使用する場合、Weviate、Milvus、Chromaが候補になります。PineconeはOSSではありませんが、開発時の体験の良さとセキュリティの堅牢さに光るものがあります。
パフォーマンス
1クエリあたりのパフォーマンス(QPS)に関しては、Milvusがリードし、WeviateとQdrantがすぐ後を追っています。ただし、レイテンシーの面では、PineconeとMilvusの両方が印象的です。Pineconeに複数のポッドを追加すると、はるかに高いQPSに達することができます。
コミュニティの強さ
Milvusは最大のコミュニティの存在を誇り、WeviateとElasticsearchが後を追います。強力なコミュニティであるほどに、より良いサポート、機能の拡張性やバグ修正等の頻度の高さへの効果が期待できます。
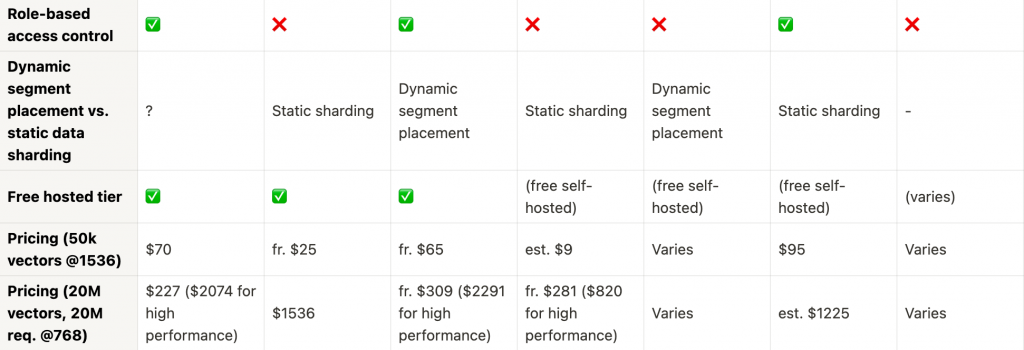
スケーラビリティ、高度な機能、セキュリティ
多くのエンタープライズアプリケーションにとって重要な機能であるアクセス制御は、Pinecone、Milvus、Elasticsearchが秀でています。スケーラビリティの面では、MilvusとChromaが動的セグメントの配置を提供しており、これにより、常に増加するデータセットに適しています。幅広いインデックスタイプのデータベースが必要な場合、Milvusが強いです。Elasticsearchはディスクインデックスサポートの面で足りないものはありますが、ハイブリッド検索は全体的によくサポートされています。
価格
限られた予算内でのプロジェクトの場合、Qdrantの50kベクターに対する推定9ドルの価格は破格です。大規模なプロジェクトの場合、PineconeとMilvusが競争力のある価格帯を提供しています。
アナリストによる分析

LLMでベクトルを活用するときに検討が必要なこと
本記事ではベクトルデータベースにフォーカスしてご紹介しましたが、LLMで追加知識を活用する場合はそれ以外にも行うべきことが多くあります。
- 追加知識の対象となる文章を事前にベクトル変換する必要があるが、どのようなモデルを活用するのか
- それぞれベクトルに変換した後にどのような手法で追加知識の候補を探索するのか
- そもそもベクトル表現が必要なのか
1.については応用先のドメインが医療や法律など専門性が高い場合、適切なベクトル表現を行うためには専門性の高いデータで学習を行ったモデルを開発する必要があります。
また、ベクトルの次元数をどのように設定するのかなど、モデル開発の難しさがそのまま課題となります。
2. について、一般的には内積計算を行うことでコサイン類似度などを算出し、文章の候補を選択しますが、データ数が多い場合に計算に時間がかかってしまう問題が発生します。
この場合には近似最近棒探索などの手法を採用する必要がありますが、この場合は最良の答えを逃してしまう可能性もあります。
従って、手法ごとにトレードオフが発生することを認識し、要件に見合った適切な選択を行う必要があります。
3.について、ベクトル計算による類似度の他にもGoogleのようなキーワードベースの検索エンジンを活用する方法もありますし、それらのハイブリッドにも検討の余地があります。
上記のようにベクトルデータベース以外で検討しなければならないことが数多いため、vectorview社が提供する情報をもとに自社にとって最適であろうサービスを素早く検討することができれば幸いです。
技術選定が難しい場合はコンサルティングサービスも提供しておりますので、以下からご連絡いただければ幸いです。
参考文献
AIベースの業務アプリ開発を専門としたコンサルサービスを提供しています。
生成AI以前から自然言語処理や対話システムを中心に研究開発してきました。対話戦略を組み込んだチャットボットや文書チェック系プロダクトの0→1開発が主領域です。
AI×医療,法律、金融、不動産分野における新規事業の創出を手掛けてきた経験から執筆します。
【所属】
株式会社サイシキ
言語処理学会(正会員)
人工知能学会(正会員)
日本メディカルAI学会(正会員)
早稲田大学人間科学学術院 招聘研究員
X(旧Twitter)も始めました、お気軽にコミュニケーションください https://x.com/shohei_fujikura
生成AI以前から自然言語処理や対話システムを中心に研究開発してきました。対話戦略を組み込んだチャットボットや文書チェック系プロダクトの0→1開発が主領域です。
AI×医療,法律、金融、不動産分野における新規事業の創出を手掛けてきた経験から執筆します。
【所属】
株式会社サイシキ
言語処理学会(正会員)
人工知能学会(正会員)
日本メディカルAI学会(正会員)
早稲田大学人間科学学術院 招聘研究員
X(旧Twitter)も始めました、お気軽にコミュニケーションください https://x.com/shohei_fujikura